AWS – Redshift – SQL exclusivos de Leader e Compute nodes
Olá pessoal,
Passamos um pouco pela arquitetura do Redshift em artigos recentes, e vimos que o Leader Node (LN) faz a ponte com os Clients. Ele pode distribuir queries para que sejam executadas nos Compute Nodes (CN) ou executar em si próprio.
Ele envia os SQLs para os CN sempre que fazem referência a tabelas que criamos (user tables) ou tables/views de sistema (com prefixo STL ou STV) e executa exclusivamente no LN aquelas que referenciam apenas as tabelas do catálogo (com prefixo PG) ou não referenciam tabelas.
Por conta desta estranha distribuição, algumas funções SQL rodam apenas nos LN (CURRENT_SCHEMA, CURRENT_SCHEMAS, HAS_DATABASE_PRIVILEGE, HAS_SCHEMA_PRIVILEGE e HAS_TABLE_PRIVILEGE) e não nos CN. O mesmo acontece no contrário, há funções SQL que só rodam quando executadas no CN (LISTAGG, MEDIAN, PERCENTILE_CONT, PERCENTILE_DISC e APPROXIMATE PERCENTILE_DISC).
Vamos ver alguns exemplos.
Uma query que não faz referência a tabelas executa no LN, portanto pode utilizar CURRENT_SCHEMA;
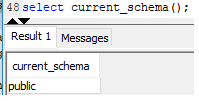
Uma query que faz referência ao catalogo (PG*), também executa no LN e pode chamar o CURRENT_SCHEMA;

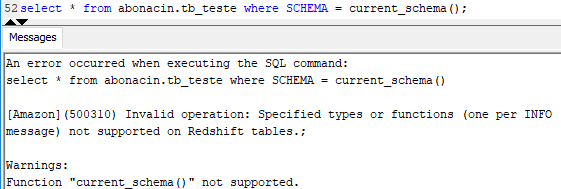
Uma query que envolve dados de usuários, executa no CN e não pode utilizar o CURRENT_SCHEMA;
Erro: [Amazon] (500310) Invalid operation: Specified types or functions (one per INFO message) not supported on Redshift tables.
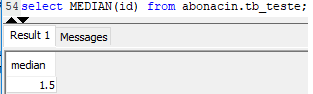
Uma query que faz referência a uma user table, pode usar MEDIAN.
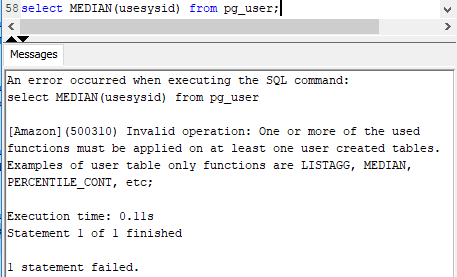
Uma query que faz referência ao catalogo, não pode usar MEDIAN.
Erro: [Amazon] (500310) Invalid operation: One or more of the used functions must be applied on at least one user created tables.
Acho que já conseguimos ter uma ideia de como funciona, não?
Até a próxima.
Você também pode gostar

Erro ao startar Apache Cassandra 2.2.16

