
Cassandra stress test
Olá Pessoal,
Vou escrever mais alguns artigos sobre Cassandra e preciso usar algumas simulações de carga. Por isso, vou começar com este artigo de como realizar um teste usando o cassandra-stress tool.
É uma ferramenta que já vem junto com as instalações Cassandra e é bastante útil no momento de calcular a capacidade do seu cluster. Ela é bastante customizável, o que faz que com seja possível reproduzir uma boa variedade de workloads e, com isso, tentar prever o impacto do GC (entre outras coisas) em seu ambiente bem como um tuning fino de sua JVM.
Vou deixar aqui registrado nosso cenário inicial, com as keyspaces abaixo. Caso queira reproduzi-lo, usamos o mesmo do artigo Deploy Cassandra AWS com Ansible.

O cassandra-stress vem com várias opções default, o que simplifica bastante nosso trabalho inicial. Assim, para um primeiro teste a gente pode tentar algo como:
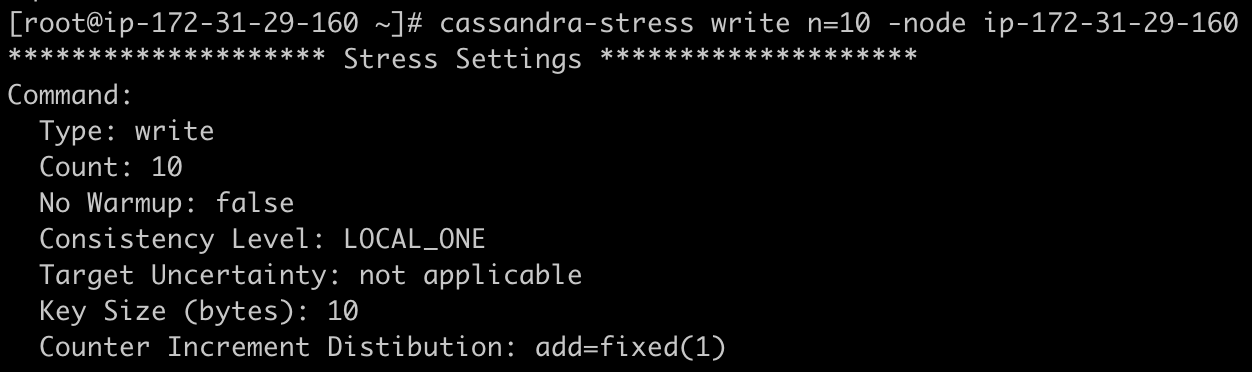
E como resultado:
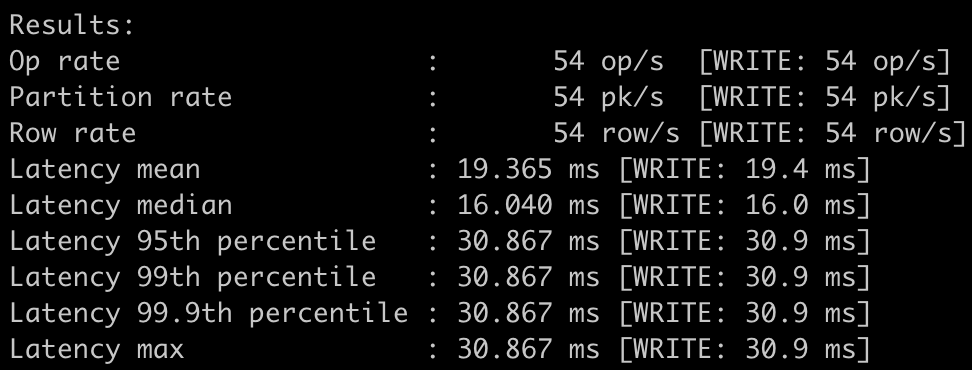
Um ponto interessante sobre a conexão é que ele usa o Cassandra Java Driver, que inicialmente bate no node que informamos, mas isto serve apenas para que a lista de nodes seja obtida. Uma vez obtida, as conexões são direcionadas para todos os nodes.

Podemos perceber a criação de uma keyspace chamada “keyspace1”, onde o cassandra-stress irá fazer suas operações.

Vamos descrever a keyspace:
cqlsh> describe keyspace1;
CREATE KEYSPACE keyspace1 WITH replication = {'class': 'SimpleStrategy', 'replication_factor': '1'} AND durable_writes = true;
Vemos que o cenário não é exatamente o que precisamos, já que normalmente temos um cluster distribuído e podemos utilizar o NetworkTopology além de aumentar o fator de replicação. A pergunta é: Como podemos customizar o cassandra-stress? Na documentação você pode encontrar vários detalhes.
A opção que mais me agrada, é uma você pode customizar o teste para que seja semelhante a sua aplicação. Você define a keyspace, as tabelas, as queries, a proporção entre escrita e leitura e várias outras coisas.
Vou mudar um pouquinho nosso cenário inicial, agora usando GossipingPropertyFileSnitch simulando então dois DCs, um para cada AZ (A e B).
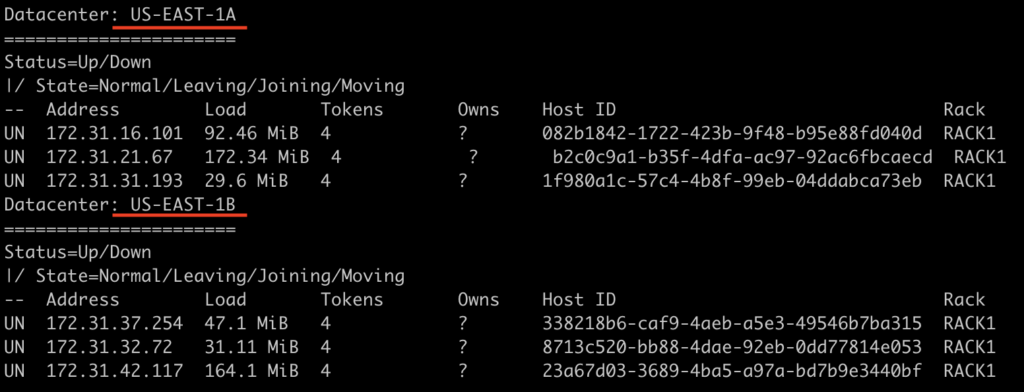
Com isso, vamos criar uma keyspace que tenha um fator de replicação 2 para cada DC. Porém, tudo será definido em um arquivo YAML
#
# Keyspace name and create CQL
#
keyspace: bonacs
keyspace_definition: |
CREATE KEYSPACE bonacs WITH replication = {'class':'NetworkTopologyStrategy', 'US-EAST-1A': 2, 'US-EAST-1B': 2};
#
# Table name and create CQL
#
table: users
table_definition: |
CREATE TABLE users (
username int,
first_name text,
last_name text,
inicio_email text,
dominio_email text,
PRIMARY KEY (username)
)
#
# Meta information for generating data
#
columnspec:
- name: username
size: fixed(10)
population: uniform(1..10M)
#
- name: first_name
size: uniform(10..20)
population: uniform(1..300)
#
- name: last_name
size: uniform(10..20)
population: uniform(1..2000)
#
- name: inicio_email
size: uniform(10..20)
population: uniform(1..10M)
#
- name: dominio_email
size: uniform(10..20)
population: uniform(1..10M)
#
# Specs for insert queries
#
insert:
partitions: fixed(1) # 1 partition per batch
batchtype: UNLOGGED # use unlogged batches
select: fixed(1)/1 # no chance of skipping a row when generating inserts
#
# Read queries to run against the schema
#
queries:
myuser:
cql: select * from users where username = ?
fields: samerow
As opções que temos agora: definir keyspaces e tabelas, como serão distribuídos/populados as colunas, quais as queries que teremos na aplicação. Feito isso, vamos colocar nosso teste para funcionar. Crie um arquivo stress.yml e execute o teste da seguinte forma:
cassandra-stress user profile=./stress.yml duration=60s 'ops(insert=1,myuser=3)' -node ip-172-31-31-193O teste vai ficar rodando um tempo e você pode aproveitar para acompanhar com alguma de suas ferramentas de monitoração se o JMX estiver habilitado, como o OpsCenter ou um VisualVM. O VisualVM permite algumas informações básicas e tem essa cara.
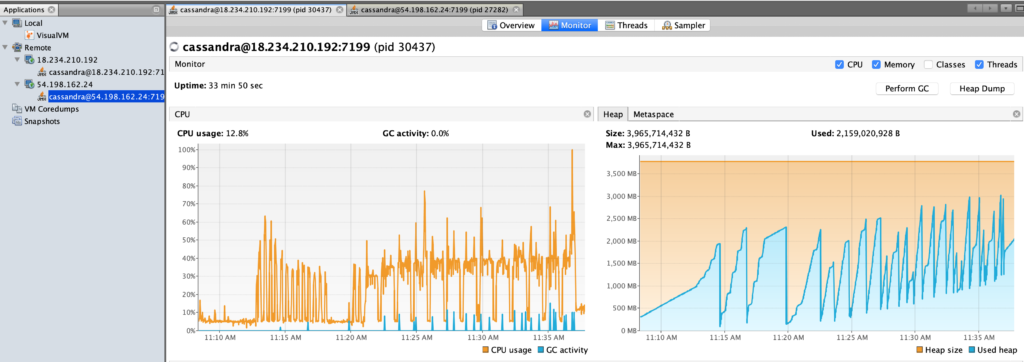
Permitindo que seja analisado com detalhes CPU/Atividade do Garbage Collector e o tamanho da HEAP, por exemplo.
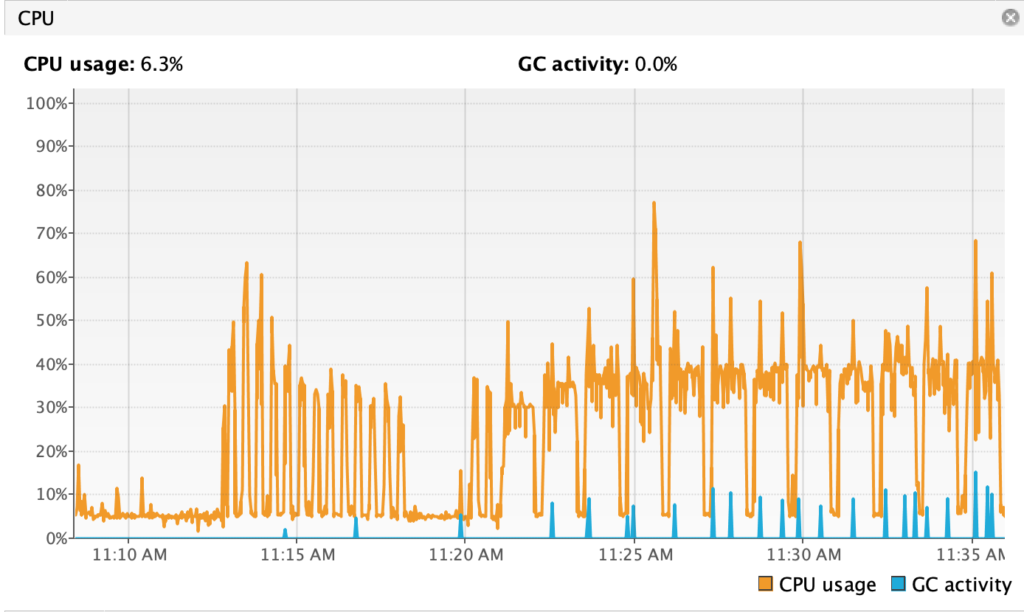
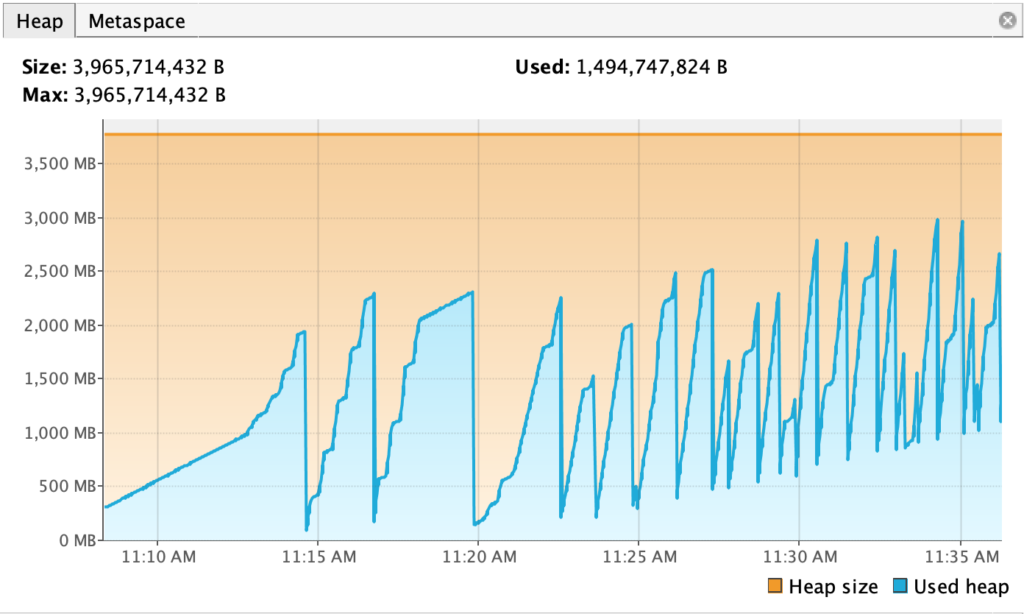
Bom, era isso. Você pode olhar a documentação para maiores detalhes de como distruir os dados em um range que faça mais sentido no seu cenário. Campos maiores, mais distribuídos, uniformemente ou normalmente (Sino) distribuídos.
Até a próxima. Dúvidas? Comente aí.
Você também pode gostar



