Cassandra: Ring, Token, Partition Key
Olá pessoal, tudo bem?
Tem alguns termos que a gente sempre escuta quando estamos falando de arquitetura do Cassandra, principalmente quando o assunto é particionar dados. Vou tentar explicar um pouquinho de alguns deles que influenciam neste particionamento.
Um cenário bastante comum é o que temos os dados distribuídos e replicados em DCs distintos, onde nem sempre a carga é exatamente igual em cada node.
Talvez você já deve ter ouvido falar que cada node é responsável por um determinado número de tokens e que de alguma forma isso influencia nesta distribuição.
A primeira pergunta que me surge é: vocês sabem exatamente onde estão e como seus dados são distribuídos em um cluster Cassandra?
Primeiramente, vamos falar dos tokens/vnodes e um pouco do período anterior a eles.
Nas primeiras versões do Cassandra (até a 1.2), você precisava calcular e indicar quais os tokens cada node possuía. Embora existam serviços na internet que ajudam nisso, era muito esforço manual.
Nas versões mais recentes, cada node pode ser responsável por mais de um token e todo o trabalho é feito automaticamente. Foi aí que surgiram os tais vnodes (virtual nodes – como se cada node no novo modelo tivesse vários nodes do formato antigo), quebrando esse paradigma de um token por node.
Quando um novo node é adicionado no cluster, durante o bootstrap, ele recebe uma quantidade de tokens (num_tokens) e em seguida recebe dos outros membros todo dado que ele será o novo responsável.
A próxima pergunta é: como a localização de cada dado está associado a estes tokens?
Tudo está baseado no nosso partition key, no ring e no algoritmo de particionamento (Partitioner).
Começando pelos Partitioners, ele é definido na criação do Cluster e não pode ser alterado. Entenda-os como uma forma de assegurar a distribuição determinística dos dados de entrada.
Até a mesma versão 1.2, o default era o RandomPartitioner, que já assegurava uma distribuição uniforme.
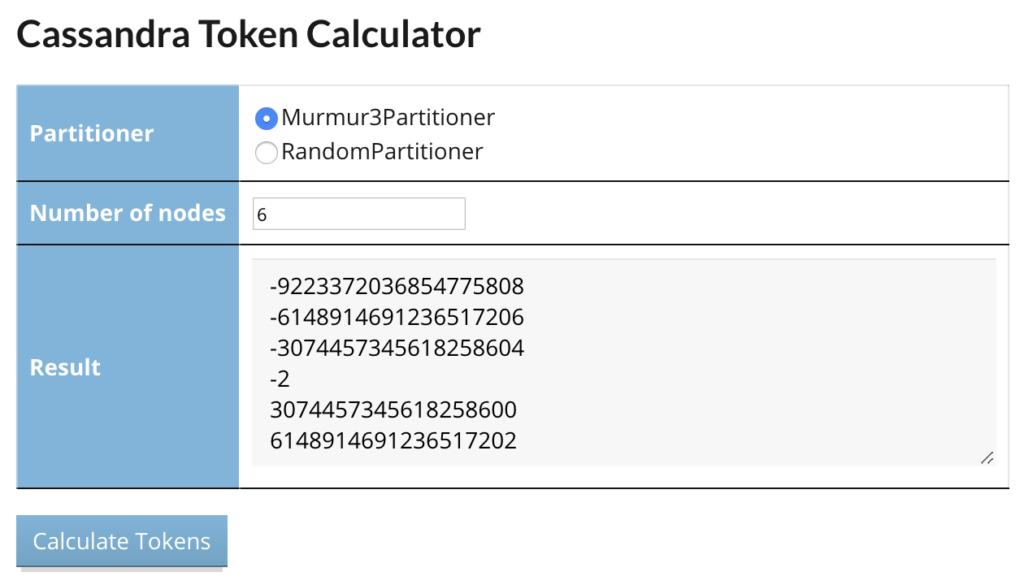
A partir da 1.2, surgiu com uma melhora significativa de performance, o Murmur3Partitioner, que usa a função MurmurHash para atribuir valores entre -2^63 to +2^63-1 para os dados da partition key. Se você não sabe o que é uma função Hash, vale a pena dar uma googlada.
De forma simplificada, o input para o partitioner é sua partition key, ele transforma este valor em um hash, e com este valor vai ser possível descobrir quem é o responsável por este dado, baseando-se nos tokens de cada node.
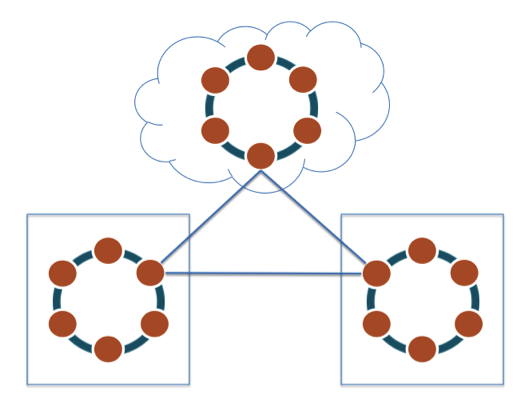
Para seguir, precisamos agora entender o conceito de ring, que é como cada token está associado a um determinado node.
Será mais fácil colocando a mão na massa. Criei um cluster com 4 nodes, divididos em 2 DCs. Para cada node, atribuí apenas 4 tokens para facilitar nossa análise.
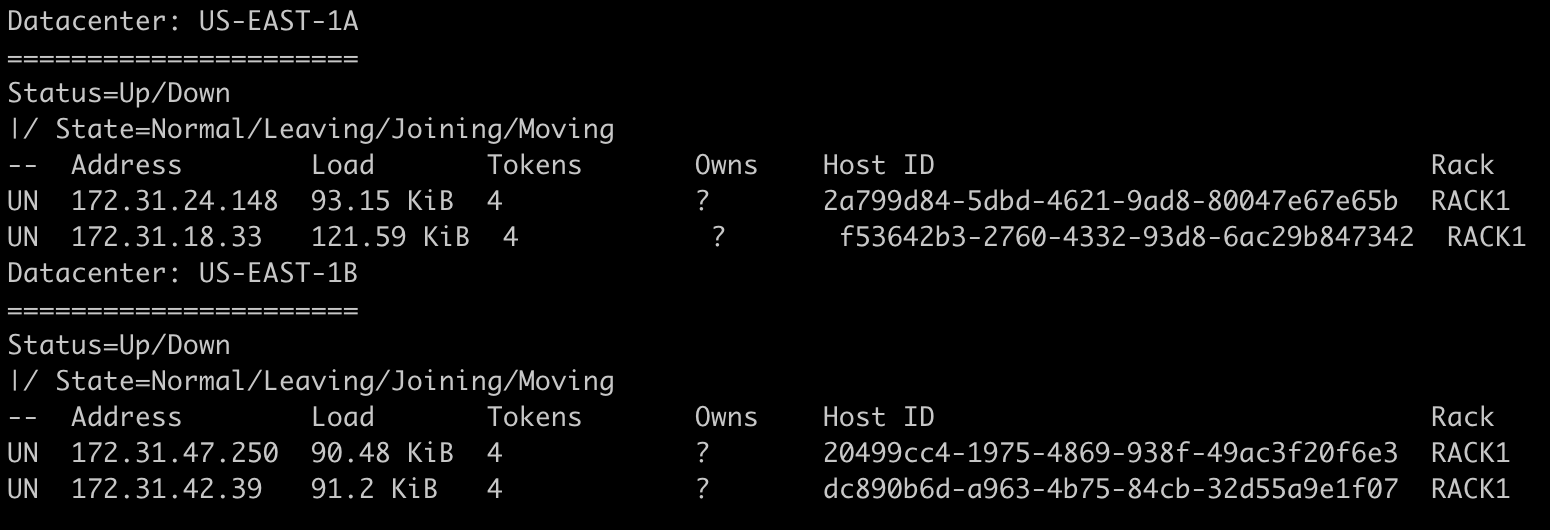
É possível então verificar quais são os tokes que marcam o final do intervalo (range) e qual o node associado, e a isto damos o nome de ring.

Agora vamos para a criação da nossa keyspace e da nossa tabela.
CREATE KEYSPACE bonacs WITH replication = {'class':'NetworkTopologyStrategy', 'US-EAST-1A': 1, 'US-EAST-1B': 1};
CREATE TABLE users (
username int,
first_name text,
last_name text,
inicio_email text,
dominio_email text,
PRIMARY KEY (username)
);
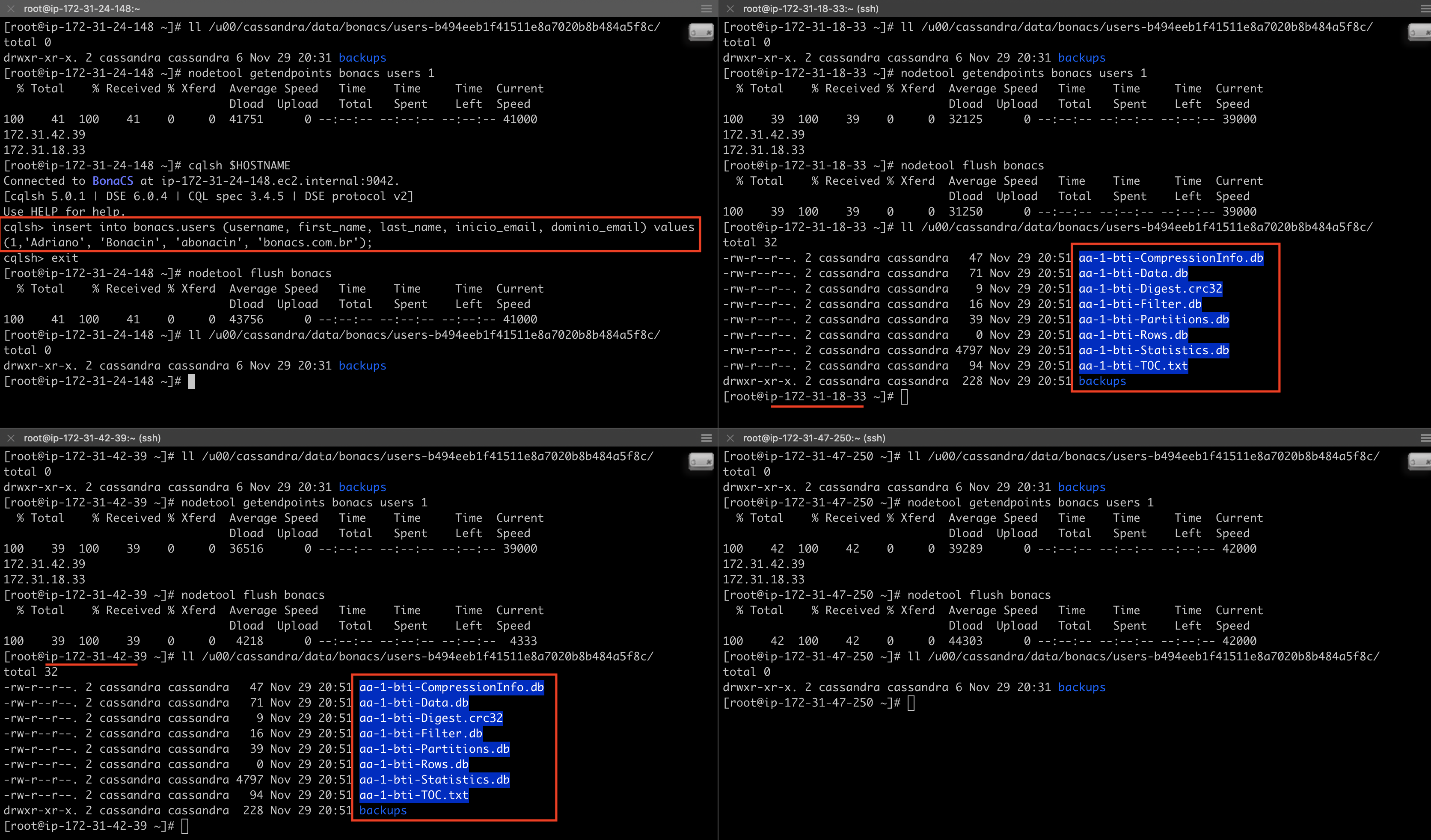
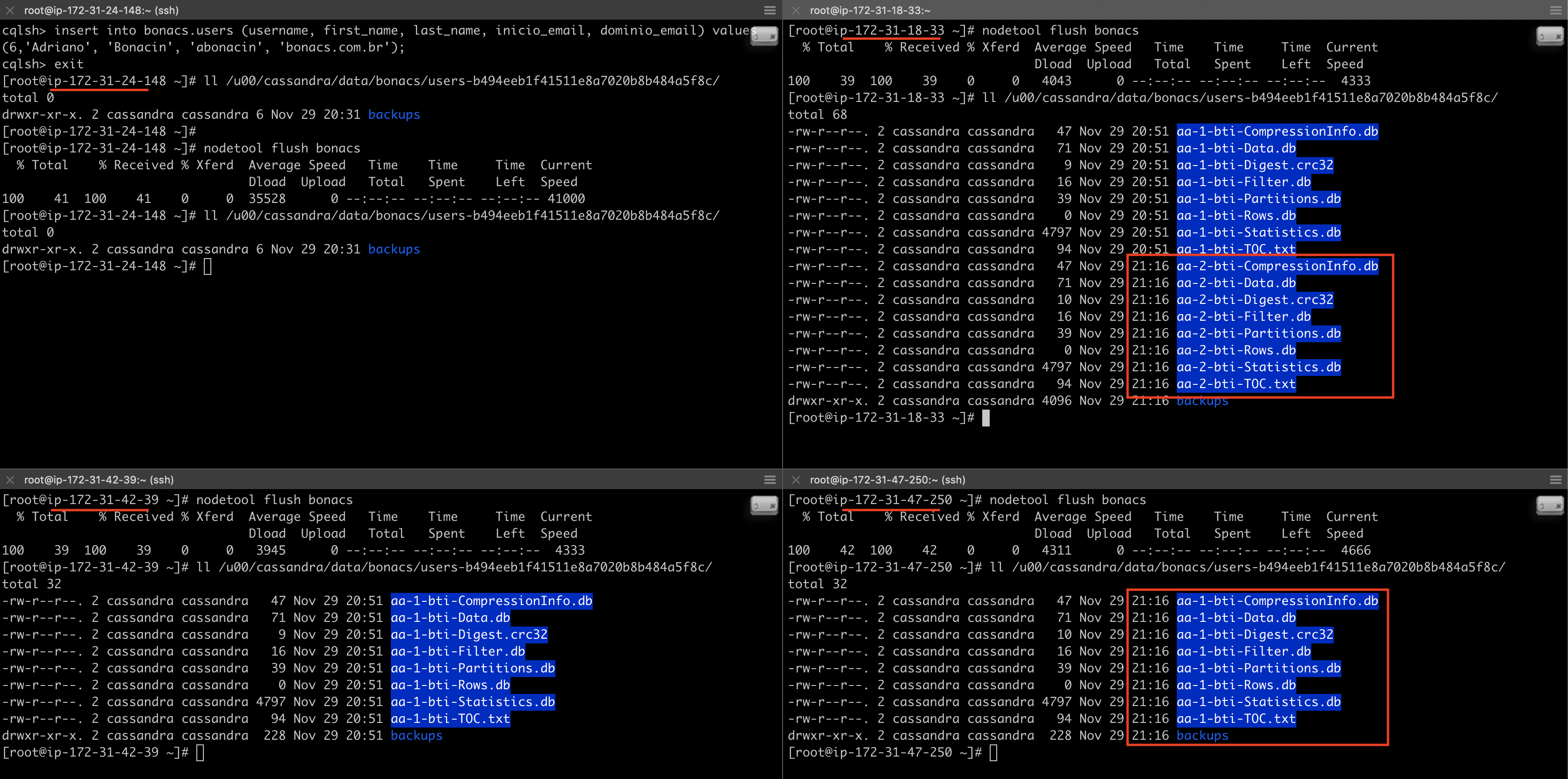
Após a criação, vamos confirmar que ainda não há SSTable.
Talvez a forma mais direta de descobrir onde para onde o dado será enviado é através do comando nodetools getendpoints, informando a keyspace, a tabela e a partition key.
Veja:

Com isso, ele diz que o node 172.31.42.39 e o 172.31.18.33 vão recebê-lo. Vamos inserir, fazer um flush e conferir?
Vamos usar uma alternativa agora para descobrir para onde o dado deve ir. Primeiro precisamos verificar qual o token associado ao 6, usando a funcão token no cqlsh.
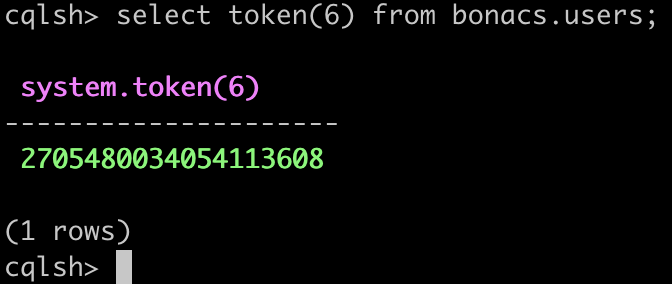
O valor retornado foi o +2705480034054113608. E onde ele se encaixa no nosso ring? Lembrando que o token associado no node marca a margem superior do range.
Na figura abaixo podemos ver que ele se encaixa no 172.31.18.33 e no 172.31.47.250.
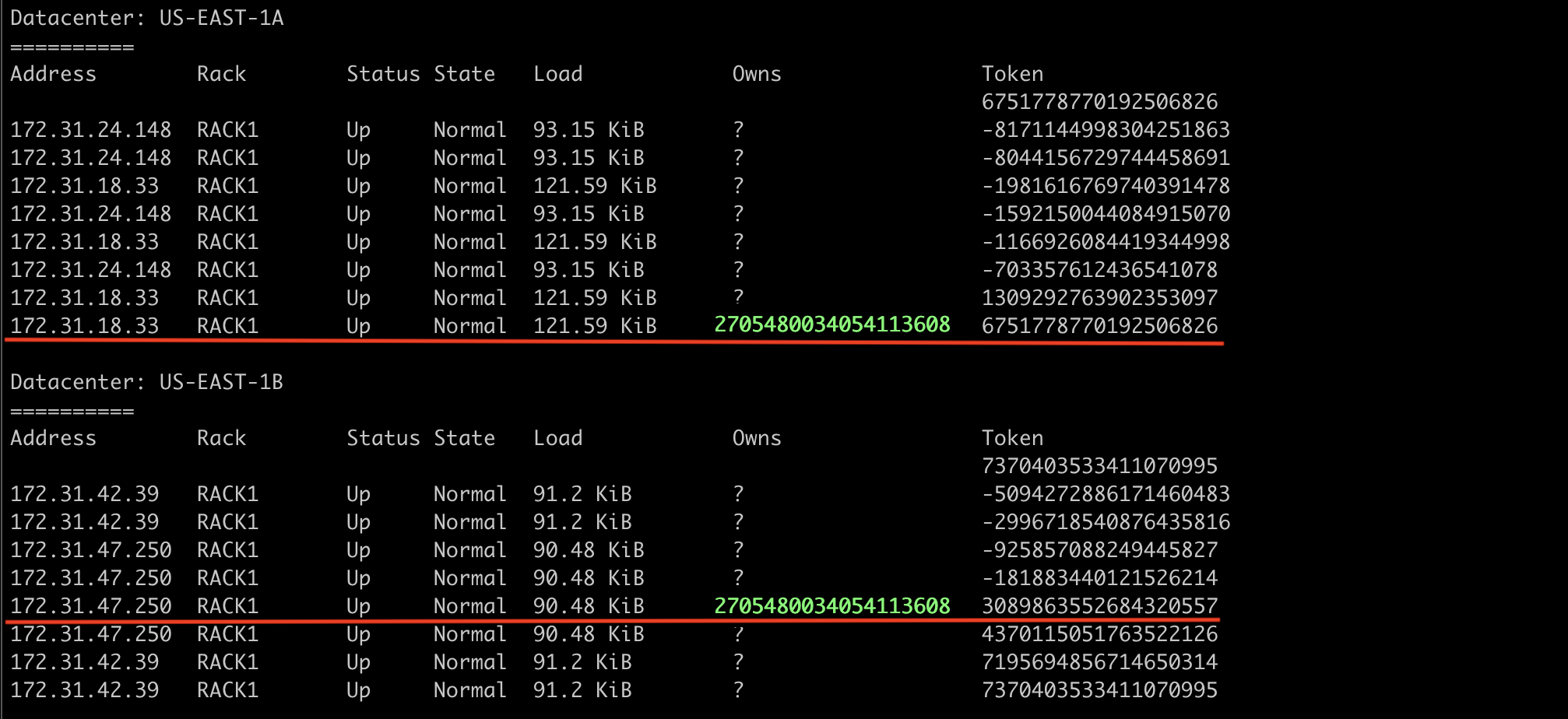
E como ficaria o getendpoints?

Vamos confirmar com um novo insert e flush.
Por último, gostaria de chamar a atenção para o número de tokens por node. Uma baixa quantidade pode ocasionar um desbalanceamento na distribuição porque os tokens são gerados aleatoriamente e nem sempre os ranges não são do mesmo tamanho.
Veja como ficou nosso cluster após um insert uniformemente distribuído e repare que nosso ring não estava distribuído tão uniforme:
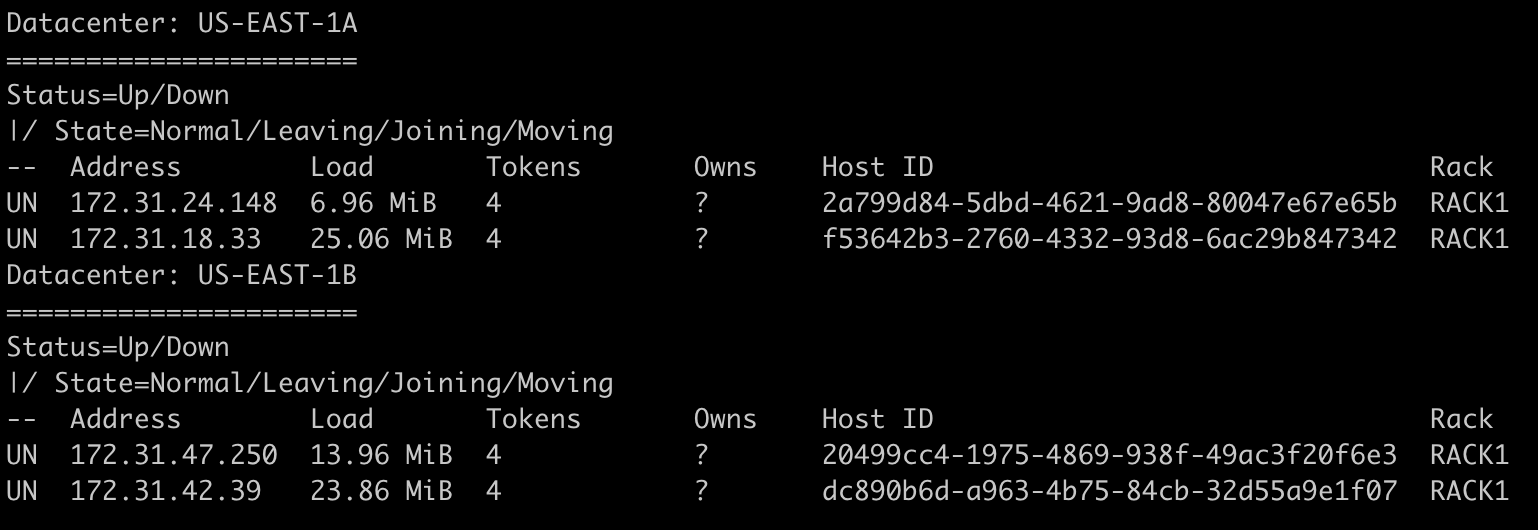
Então pense assim: ranges maiores recebem mais dados. Da mesma forma, espera-se que quanto mais tokens um node tenha, mais dados ele receba.
Era isso, gostou? Até a próxima.
Tag:cassandra, partitionkey, ring, token, vnode
Você também pode gostar



